Webボット解説サイト
1. はじめに
Webボットとは、ネットワーク上で動作するコンピュータプログラムです。 Webボットは、一定の動作を自動的に実行する際に使用されます。 実際に検索エンジンやカスタマーサービスなどに利用されています。 しかし、特定の商品の買い占めやアカウントの乗っ取りなどの悪意のある行為にWebボットを悪用する事例が増加しています。
そこで、本サイトでは、1人でも多くの方にWebボットとそれに関連する研究について知ってもらうために、Webボットやその活用例と悪用例、検知手法と検知ツールについて紹介します。
また、本サイトで紹介する悪用例などについては、ご自身の環境以外で絶対に行わないようにしてください。 仮に、本サイトで得た知識を利用した行動によって損害を被ったとしても、我々は責任を負いかねますのでご了承ください。
対象:情報処理技術者の方、明治大学 情報セキュリティ研究室に所属している方
キーワード:Webボット、JavaScript、reCAPTCHA
2. 基礎知識
2.1 Webボットとは
Webサイトの閲覧の際、一般的に、人間の操作の場合、検索エンジンの利用するかもしくは、目的のWebサイトのURLの入力などにより、対象のWebサイトへアクセスすることが多いかと思います。 Webサイトの閲覧の一連の操作は、プログラムによって、大量の処理を自動かつ高速で行うことができます。 このプログラムをボットと呼びます。 本サイトでは、WebスクレイピングやWebサイトの監視などを行うボットを対象とし、これらをWebボットと定義します。
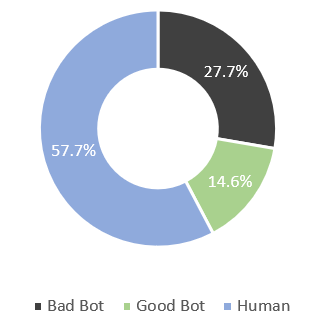
ここで、図1に、Imperva社が作成したWebボット関連の報告書であるBad Bot Report 2022内の2021年におけるトラフィックの割合を示します。 この図を見ると、2021年の全トラフィック中の42.3%がWebボットであり、その中の27.7%は悪質なWebボットであったという調査結果があります。
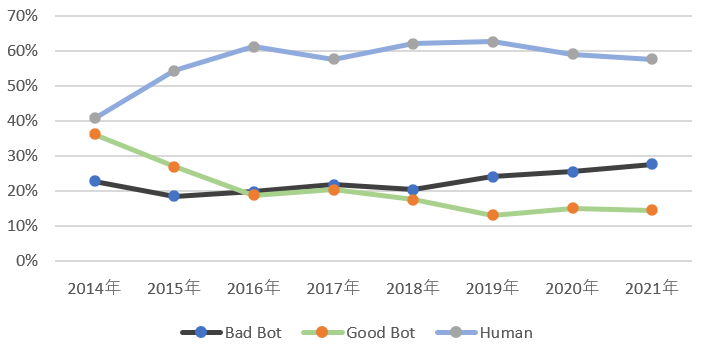
また、図2に、同報告書の2014~2021年におけるトラフィックの割合を示します。 この図を見ると、2017年頃から悪質なWebボットの割合が増加傾向にあることが分かります。
このように、過去ではWebボットの正しい活用が一般的でしたが、Webボットの悪用も増加しています。
2.2節、2.3節では、Webボットの活用例と悪用例をそれぞれ具体的に説明します。
2.2 Webボットの活用例
世の中には、様々なWebボットの利用方法があります。 例えば、Webスクレイピングによる情報収集やWebサイトの監視、Webアプリケーションの動作検証が挙げられます。 これらについて、表1で説明します。
| 例 | 説明 |
|---|---|
| Webスクレイピングによる情報収集※ | Webボットを用いて目的のWebサイトから特定の情報を集め、それらをまとめる処理を行います。 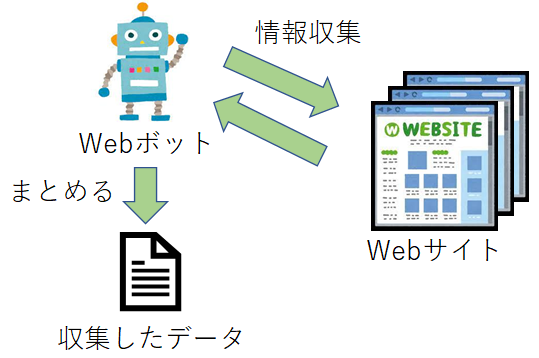 |
| Webサイトの監視 | WebサイトのパフォーマンスをWebボットで確認し、問題が発生すると管理者に報告します。 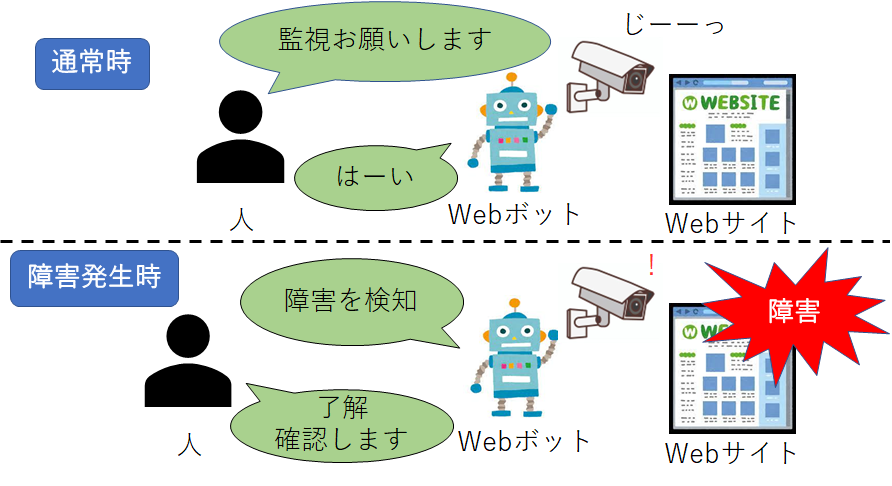 |
| Webアプリケーションの動作検証 | WebアプリケーションのテストをWebボットで自動化します。 これによって、手動で毎回テストするよりも効率的に行うことができます。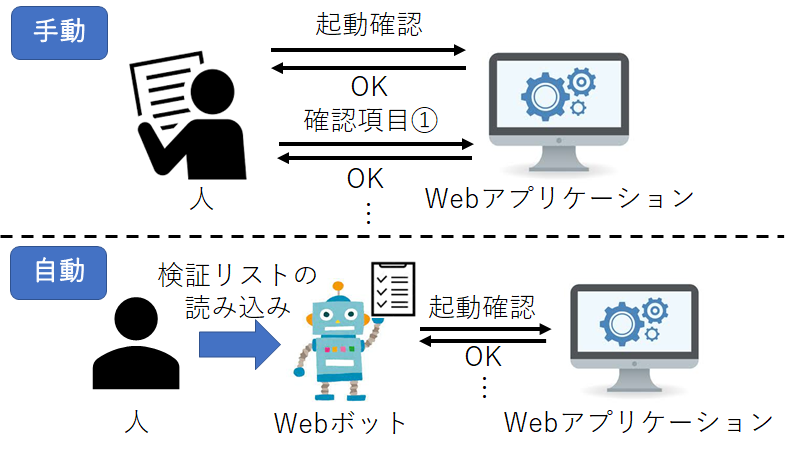 |
※ Webサイトには許可のないWebスクレイピングを禁止している場合があります。 具体的には、Amazonや楽天、Twitter等のSNSなどです。 これらのWebサイトがWebスクレイピングを禁止するのは、Webスクレイピングによるサーバへの高負荷、著作権の侵害、取得した情報の不正使用などを考慮しているからです。
2.3 Webボットの悪用例
2.2節で紹介したように、Webボットは正しく利用すればとても便利なツールです。 しかし、Webボットは悪用されることも多々あり、問題となっています。例えば、転売目的の買い占めやDoS攻撃、クレデンシャルスタッフィングが挙げられます。 これらについて、表2で説明します。
| 例 | 説明 |
|---|---|
| 転売目的の買い占め※ | Webボットを用いてECサイトにアクセスし、目的の商品(主に限定品)を手動よりも速く自動で大量購入します。 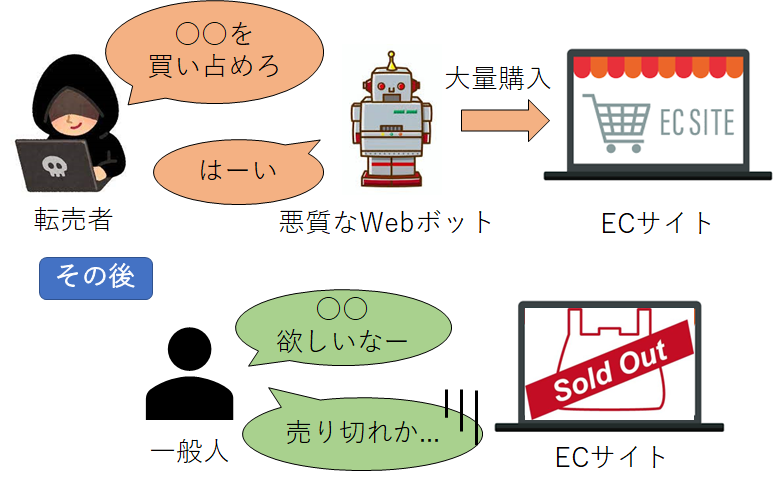 |
| DoS攻撃 | あるコンピュータからボットを用いて、対象のサーバに対して大量のアクセスを行います。 これによって、サーバに負荷をかけ、サイトの運営や閲覧を妨害します。 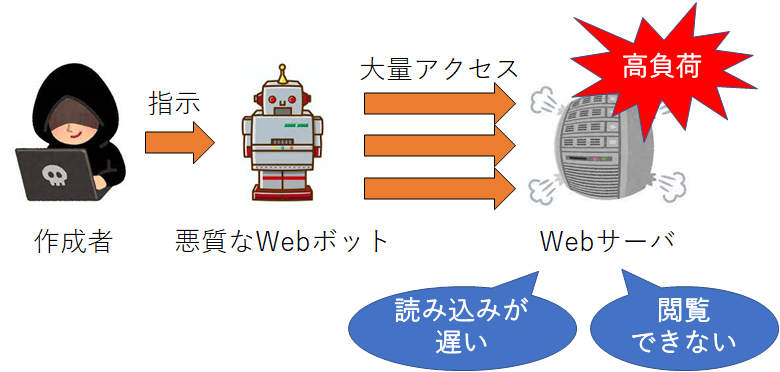 |
| クレデンシャルスタッフィング | ユーザ名、パスワードなどの前もって取得した情報を用いて、ログイン画面からアカウントに不正にログインする操作をWebボットで自動化します。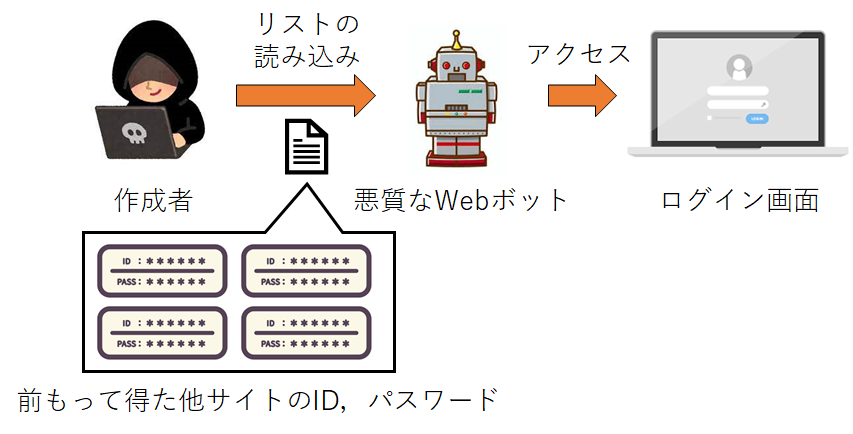 |
※ 日本経済新聞やITmediaの記事によると、実際に家庭用ゲーム機やイベントチケットの販売サイトに対して、転売者がWebボットを悪用して買い占めを行い、一般の方が購入できなくなるという事例が発生しています。
このように、Webボットの悪用による被害が実際に起こっているので、Webボットの検知を行って被害の拡大を防ぐ必要があります。
Webボット検知とその検知技術については、3節で説明します。
3. Webボット検知
3.1 Webボット検知とは
Webボット検知とは、Webサーバ側でWebボットからのアクセスを検知することです。 前節で説明したように、転売目的の買い占めを始めとして悪質なWebボットによる被害は我々の普段の生活にも拡大しており、今では無視できない存在になっています。 悪質なWebボットを検知することは企業だけでなく、我々の生活の利益にもつながるので、重要です。
また、Webボットを高精度で検知するだけではなく、人からのアクセスを誤検知しないことや人がWebサイトを利用する上で手間がかからないようにすることも求められています。
具体的な検知技術ですが、悪質なWebボットの技術が巧妙化しているため、検知を行う技術も様々なものがあります。 3.2節、3.3節ではパケットやJavaScriptを用いた検知についてそれぞれ説明します。
3.2 パケットを用いた検知
サーバ上のログには、アクセスしてきたクライアントのIPアドレスや通信のやり取りをした際のHTTPヘッダなど多くの情報が含まれています。 そのログを見ることで様々な情報を得ることができます。
3.2.1節、3.2.2節では、明治大学 情報セキュリティ研究室の現段階の調査結果に基づいてIPアドレスとHTTPヘッダを用いた検知技術を紹介します。
3.2.1 IPアドレスによる検知
ここでは、IPアドレスを利用した検知手法を紹介します。
同じIPアドレスからのアクセス回数の確認
Webボットは短時間で同じ処理を繰り返して、大量にアクセスすることができます。 そのため、IPアドレスを変更せずに実行することが多いです。 よって、同じIPアドレスから大量にアクセスしている場合はWebボットの可能性が高いと言えます。
スパム不正利用データベースで検索
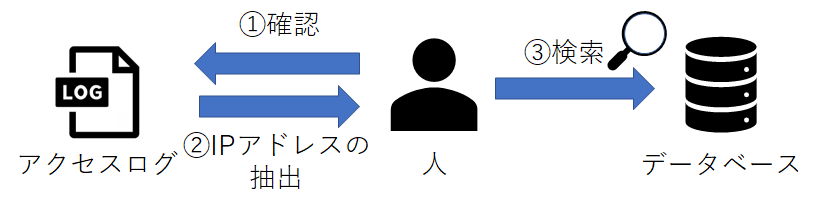
過去に悪質なWebボットを用いてWebサイトにアクセスしたと判明した際に、そのIPアドレスをデータベースに記録して、サービスとして提供している企業があります。
ここでのデータベースとは、疑わしいと判断されたIPアドレスをリスト化したものです。 ログにあるIPアドレスをデータベース内で検索し、登録されているIPアドレスと一致するか確認します。 図3にその様子を示します。
サービスを提供している企業の例として、SpamhausやDataDome、Udgerが挙げられます。 これらについて、表3で説明します。
| 例 | 説明 |
|---|---|
| Spamhaus | スパムメールの送信元やISPがユーザに割り当てるIPアドレスの範囲などの情報が登録されています。 |
| DataDome | ミリ秒単位でデータを更新しています。 また、機械学習を用いて、あるIPアドレスがボットに使用されている確率を計算します。 |
| Udger | 最終確認時間、クローラー名、IPアドレス、ドメイン名、データセンター、国名が登録されています。 |
クラウド上で動作しているか確認
IPアドレスは、CMANなどのインターネットサービスやwhoisコマンドによって、その所有者の所属する国や組織などの情報を確認することができます。
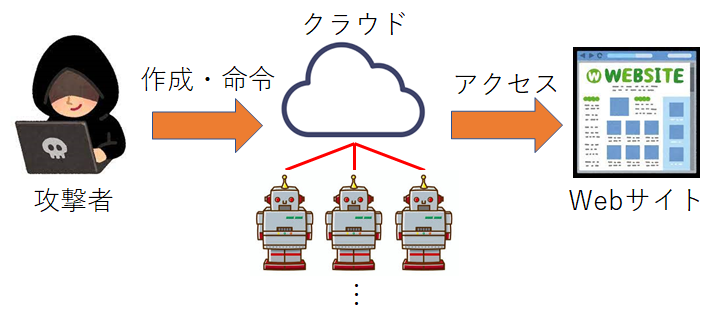
Webボットの作成者は自身の環境ではなく、クラウド上でWebボットを動作させる場合があります。 図4にその様子を示します。 この場合の利点として、低コストで大量のWebボットを配置し、実行可能な状態で待機させることができます。 よって、作成者が攻撃したい時にすぐにWebボットを使用できるようになるため、準備の手間を省くことができます。 また、一般の利用者はクラウドを使ってWebサイトにアクセスすることは少ないため、クラウドを経由している場合はWebボットの可能性があります。
3.2.2 HTTPヘッダによる検知
HTTPヘッダとは、HTTPリクエスト、レスポンスでやり取りするデータに関する情報が記されている部分です。 具体的には以下の観点から、アクセス対象がWebボットかどうかの判別を行います。
HTTPヘッダ内の情報の確認
Google ChromeやMicrosoft EdgeなどのWebブラウザを使用する場合とWebボットを使用する場合では、送信するHTTPヘッダ内の情報が異なる場合があります。
Google Chromeのヘッドレスブラウザ※(以降、Headless Chromeと呼ぶ)を例に挙げます。 Headless Chromeの場合、HTTPリクエストを送信する際のヘッダ内にaccept-languageヘッダが存在しません。 よって、この情報がWebボットを検知する判断材料の一つになっています。
※ ヘッドレスブラウザとは、GUIを持たないWebブラウザであり、通常よりもWebサイトに描画する時間が減るので、処理が軽くなります。 これをWebボットに利用することで、より高速に動作することが可能になります。
プロキシヘッダの確認
プロキシ※を用いることで、アクセスログに残るIPアドレスがプロキシのIPアドレスになるなどクライアント側は匿名性を確保できるので、安全に接続できます。 しかし、このプロキシの仕組みを悪用することで3.2.1節で説明したIPアドレスによる検知を困難にしてしまいます。
実際に、Webボットのアクセスにデータセンタープロキシを用いる場合があります。
DataDome社のブログによると、データセンタープロキシが大規模な攻撃のために大量のIPアドレスを必要とするWebボットに用いられていると述べられています。
よって、プロキシを使用した際に付与されるヘッダであるプロキシヘッダの有無はWebボットを検知する判断材料の一つになります。 ここでは、具体的なプロキシヘッダの値として、ForwardedとProxy-Authorizationを紹介します。
- Forwarded
プロキシが使用された際にクライアントのIPアドレスなどの情報を公開するヘッダです。 - Proxy-Authorization
プロキシサーバに対してUser-Agentを認証するための認証情報を保持するヘッダです。
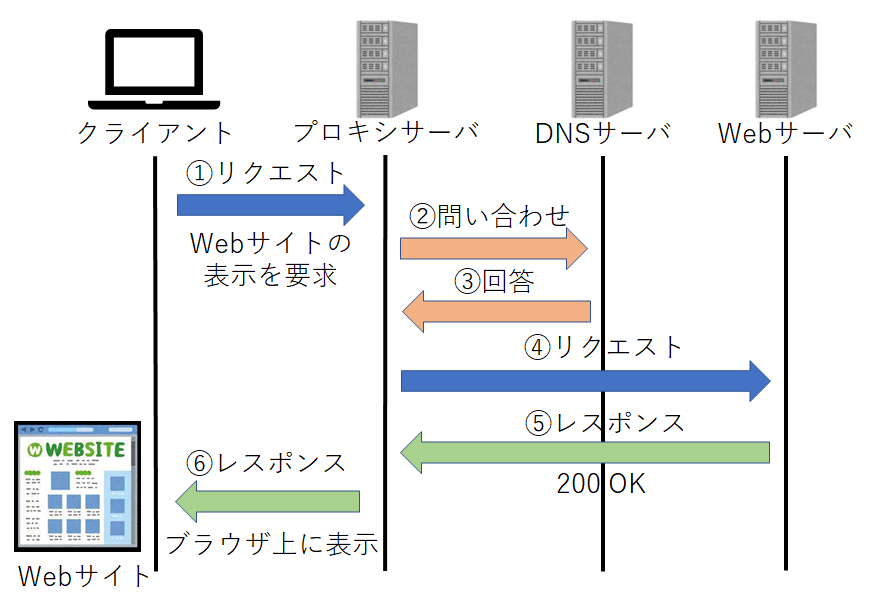
※ プロキシとは、クライアントからサーバへの接続を代理で行うシステムです。 図5にプロキシを用いた接続を示します。この時、クライアントやサーバ間の接続が確立されているものとします。
HTTP Refererの確認
HTTP Referer※から現在のページにアクセスする前のページのURLを取得し、そのページの内容からアクセスしている対象がWebボットかどうか判断します。
もし、Refererが目的のWebサイトにアクセスする上でそれと関連するサイト、もしくは検索エンジンの場合、特に怪しい点はありません。 しかし、関連性があまりないWebサイトの場合、闇雲に適当なWebサイトを順にアクセスしている可能性があるので、Webボットの可能性が高いです。
例えば、RefererがあるWebサイトAのURLであり、サイトA内には本サイトにアクセスするリンクが無かったとします。 この場合、サイトA内のリンクを辿って本サイトにアクセスしてきたとは考えにくく、予め用意されたURLを辿っているのではないかと推測されます。 よって、この例ではアクセス対象がWebボットである可能性が高いです。
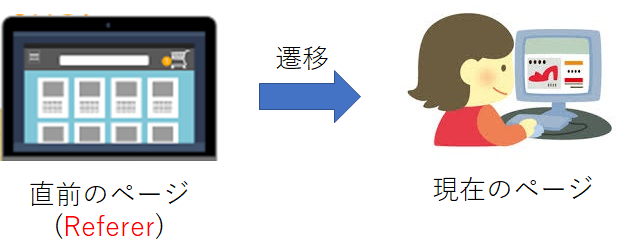
※ Refererとは、クライアントから現在リクエストされているWebページのリンク元のURLです。 例えば、図6のように現在、あるユーザがECサイトにアクセスし、商品一覧から気になる商品をクリックしてその商品の詳細を見ているとします。 この場合、商品一覧が表示されている画面のURLがRefererとなります。
User-Agentヘッダの確認
curlやPythonなどWebブラウザ以外のライブラリを用いてHTTPリクエストを行った場合、 User-Agent※ヘッダの値にcurl、もしくはPythonの文字列とそのバージョンが含まれています。 よって、これを確認することでWebブラウザ以外のライブラリからのリクエストと判別することができます。
※ User-Agentとは、Webサイトにアクセスした際にクライアントが使用しているOSやWebブラウザの情報です。
3.3 JavaScriptを用いた検知
JavaScriptとは、主にWebブラウザ上で動作するプログラミング言語です。 Webブラウザ上でJavaScriptを実行することで、主にヘッドレスブラウザを用いた場合のWebボットを判別する材料となるデータを収集することができます。 図7にその様子を示します。 なお、ここではHeadless Chromeを検知の対象としています。
また、Windows 10 Homeで通常のブラウザ(Google Chrome)とWebボット(Headless Chrome)を使用した場合のプロパティの値をそれぞれ表4、表5に示します。
※ 今回、プロパティの表示に使用したWebサイトはOS:Ubuntu 20.04.4 LTS、Webサーバソフト:Apache 2.4.41で構築されています。
| 項目 | 値 |
|---|---|
| Webdriver | false |
| User-Agent | Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.0.0 Safari/537.36 |
| navigator permissions | denied |
| Notification permission | denied |
| window.chrome | [object Object] |
| plugin length | 5 |
| webGL Vendor | Google Inc. (AMD) |
| webGL Renderer | ANGLE (AMD, AMD Radeon(TM) Graphics Direct3D11 vs_5_0 ps_5_0, D3D11) |
| hairline | supported |
| MimeType length | 2 |
| RTT | 100 |
| 項目 | 値 |
|---|---|
| Webdriver | true |
| User-Agent | Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) HeadlessChrome/108.0.5359.95 Safari/537.36 |
| navigator permissions | prompt |
| Notification permission | denied |
| window.chrome | undefined |
| plugin length | 0 |
| webGL Vendor | Google Inc. (Google) |
| webGL Renderer | ANGLE (Google, Vulkan 1.3.0 (SwiftShader Device (Subzero) (0x0000CODE)), SwiftShader |
| hairline | not supported |
| MimeType length | 0 |
| RTT | 0 |
以降では、表4、表5で示されたプロパティについて説明します。
navigator.webdriver
navigator.webdriverは、Webブラウザが自動で操作されているかを示すものです。 この値がtrueだと、Webブラウザが自動で操作されていることを示します。
このプロパティは、ヘッドレスに関係なく自動制御されている場合、trueとなります。
navigator.userAgent
3.2.2節で紹介したUser-Agentですが、JavaScriptではこの値をnavigator.userAgentから確認することができます。
Headless Chromeの場合、「HeadlessChrome」という文字列が含まれます。
navigator.permissions
ここでは、navigator.permissions.query({ name: 'notifications' }).stateとNotification.permissionを用います。 これらはどちらも、ユーザのWebサイトにWeb通知を表示するかどうかの許可状態を表すものです。 異なる点としては、Notification.permissionは読み取り専用のデータで変更はできません。
通常のブラウザの場合、これらは同様の値を示します。
しかし、Headless Chromeの場合、これらの値が"prompt"、"denied"と異なっており、矛盾します。
window.chrome
window.chromeは、Google Chromeの拡張機能の情報を有するものです。 拡張機能の例として、Google翻訳やGoogle Dictionaryなどが挙げられます。
Headless Chromeの場合、この値は存在しません。
navigator.plugins
navigator.pluginsは、Webブラウザの拡張機能の情報を保持しているリストです。 通常のWebブラウザにはいくつかの拡張機能が最初から備わっています。
しかし、Headless Chromeの場合、拡張機能が存在しません。 すなわち、navigator.plugins.lengthの値が0になります。
また、navigator.pluginsは通常のブラウザの場合、PluginArrayというオブジェクトを用いて定義されています。 PluginArrayは、使用可能な拡張機能のリストが参照しているオブジェクトです。
Headless Chromeの場合、PluginArrayを用いて定義されていません。
WebGL Vendor、Renderer
WebGL(Web Graphics Library)とは、任意のWebブラウザ上で2次元や3次元のコンピュータグラフィックをレンダリングするためのJavaScript APIです。 また、VendorはWebGLを提供している企業、RendererはWebサイトを構成するHTMLなどのコンピュータが認識できるデータからユーザが認識できる表示に変換するプログラムです。
Headless Chromeの場合※、Vendorが"Brian Paul"、Rendererが"Mesa OffScreen"となる可能性が高いです。
※ 全てのHeadless Chromeがこれらの値を示すとは限らないので、あくまで一例であることを留意してください。
Modernizr.hairline
Modernizr.hairlineは、ModernizrというJavaScriptのライブラリ内のメソッドで、Webブラウザに対して様々なHTML、CSS機能の存在をテストすることができます。
Headless Chromeの場合、幅が1ピクセル以下のCSSボーダー※の扱いを検出するhairline機能がありません。
※ CSSボーダーとは、HTMLの要素に引く枠線を設定するプロパティです。
navigator.mimeTypes
navigator.mimeTypesは、Webブラウザで認識されているMIMEタイプのリストを返すプロパティです。
通常のWebブラウザの場合、複数のMIMEタイプが認識されています。
しかし、Headless Chromeの場合、navigator.mimeTypes.lengthの値が0になります。
navigator.connection.rtt
navigator.connection.rttは、RTT※値を返すプロパティです。
Headless Chromeの場合、この値が常に0になります。
※ RTT(Round Trip Time)とは、通信相手に信号やデータを発信してから、応答が返ってくるまでにかかる時間です。
MouseEvent.movementX、movementY
MouseEvent.movementX(Y)は、現在と直前のマウスのX(Y)座標の差を取得するプロパティです。
Headless Chromeの場合、これらの値が0になります。
このプロパティは表4、表5内にはありませんが、マウスの動きからWebボットを検知する際に用いられます。
4. Webボット検知ツール
3節でWebボット検知手法について紹介しましたが、実際、これらの手法を個別に実装するのは大変です。 しかし、Webボット検知を行うためのツールが存在します。 このツールを利用することで、誰でも簡単にWebサイト内でWebボット検知を行うことができます。
ここでは、それらのツールを紹介します。
BotD
BotDは、Fingerprint社が開発しているツールで、Webボットからのアクセスをリアルタイムで検知することができます。 また、本ツールには無料版と有料版があり、無料版はAPIの呼び出しが1ヶ月につき300万回と制限されています。
図8は、Fingerprint社が運営しているBotDのデモサイトをアクセスした結果として表示された画面です。 右側に「You are not a bot」と表示されており、Webボットかどうかの判定がされているのが分かります。
より詳しく知りたい方はデモサイト上にBotDに関する情報が記載されているので、そちらを参照してください。

FPScanner
FPScannerは、DataDome社の開発責任者が公開しているWebボット検知ツールです。 これは、WebサイトにアクセスしてきたクライアントのWebブラウザの情報をJavaScriptを用いて取得し、Webボットの判別を行います。
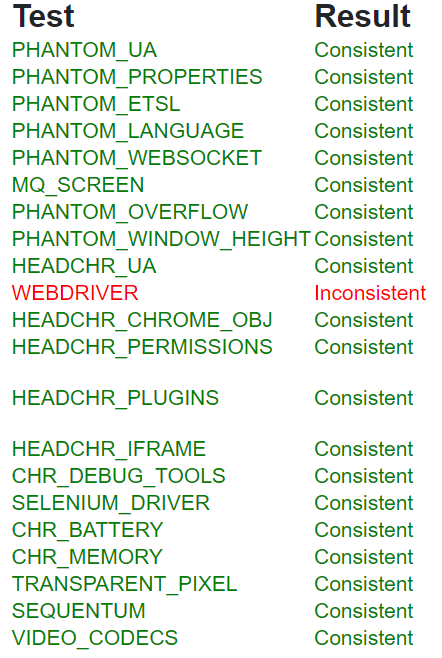
図9は、DataDome社の研究責任者の方が運営しているFPScannerのデモサイトをアクセスした結果として表示された画面です。 画面の左側にプロパティが並べられており、右側に各プロパティの値について判定結果が表示されています。
より詳しく知りたい方はこの方のGitHub上にFPScannerに関する情報が記載されているので、そちらを参照してください。
reCAPTCHA
reCAPTCHAは、Google社が提供している悪意あるソフトウェアがWebサイトでの不正な活動を行うのを防ぐサービスです。 図10は、最新版のreCAPTCHA v3を使用した際に左側の矢印の部分をマウスオーバーすると表示されます。
reCAPTCHA v3では、ユーザを妨げることなく、Webサイト上のユーザの行動がどの程度不審であるかを示すスコアをWebサイト管理者に渡します。 また、この時に得たユーザの行動を学習して、以降のスコア算出の精度を向上させます。
スコアは0.0~1.0の値を使用し、0.0に近いほどボットである可能性が高くなります。 また、サービス利用者はスコアの閾値を設定できます(デフォルトでは0.5)。 閾値によってユーザを人と判断するか、2段階認証による追加の確認を行うかなどの分岐処理を決定します。

出典:Google reCAPTCHAの使い方(v2/v3)
5. まとめ
Webボットに関する情報やその検知技術、検知ツールについて紹介しました。 Webボットはサービスの向上に貢献できる便利ツールですが、一方で、その利便性の高さを悪用されることがあります。 本サイトの内容を基に、悪質なWebボットからのアクセスの基本的な対策方法を知って頂ければと思います。
最後になりますが、本サイトが皆様のお役に立てれば幸いです。
参考文献
- 2022-Imperva-Bad-Bot-Report(閲覧 2023/01/19)
- On the Architecture of Bot Detection Services(閲覧 2023/01/19)
- reCAPTCHA v3 の紹介: bot の活動を阻止する新しい方法(閲覧 2023/01/19)
- 12 Ways to hide your Bot Automation from Detection | How to make Selenium undetectable and stealth | PiProgramming(閲覧 2023/01/19)
- 6 Ways to detect a headless Browser with JavaScript | How to detect a Headless Browser | PiProgramming(閲覧 2023/01/19)
- infosimples/detect-headless: Access https://infosimples.github.io/detect-headless to run several headless detection tests against your browser.(閲覧 2023/01/19)
- Detecting Chrome Headless (antoinevastel.com)(閲覧 2023/01/19)
- Detecting Chrome Headless, new techniques(閲覧 2023/01/19)
- HTTPヘッダー - HTTP(閲覧 2023/01/19)
- ボット(bot)とは?どのような種類があるのか? - NordVPN(閲覧 2023/01/19)
- border - CSS:カスケーディングスタイルシート(閲覧 2023/01/19)
- Webスクレイピング禁止サイト5選!違法にならないスクレイピング方法とは(閲覧 2023/01/19)
- topcourt(閲覧 2023/01/19)
- インターネットボットはどのように構築されるのか?(閲覧 2023/01/19)
- ボットとは?ボットの定義(閲覧 2023/01/24)
- WebGL:ウェブの2Dおよび3Dグラフィック - Web API(閲覧 2023/01/31)
- Vastel, Antoine, et al. "FP-Crawlers: studying the resilience of browser fingerprinting to block crawlers." MADWeb'20-NDSS Workshop on Measurements, Attacks, and Defenses for the Web. 2020.
制作 2023 明治大学情報セキュリティ研究室 「Webボット解説サイト製作委員会」Ver 1.0.0
更新日時 2023/02/15
Follow me!
